※ Open Samizdat
ChatGPT Survey: Performance on NLP datasets
Abstract The popularity of ChatGPT and its various impressive capabilities lead some people to believe that it is a significant step forward for linguistic capabilities over existing systems, that the field of NLP will soon be consumed by generative language models, or even that it foreshadows AGI. To test these claims, I conducted a survey of the arXiv pre-prints that compare ChatGPT with other approaches, mainly with smaller fine-tuned models. ChatGPT’s performance is not as impressive as I expected, as it is often outperformed by significantly smaller models.
⁂
Methodology
As of 2023-03-23, a search for
chatgpt on arXiv returned 141 papers. To filter out irrelevant papers, I ignored those that did not seem to be about NLP research or those that discussed non-performance aspects, such as ChatGPT’s political leaning. I then opened the remaining papers and scrolled through them, looking for a table or figure that provides a quantitative comparison between ChatGPT and other models. I found 19 papers that met these criteria. The tables and figures from these 19 papers are in the Appendix below, along with a brief commentary. For each paper, I counted for how many datasets ChatGPT obtained a better score than the best performing non-LLM method . If a dataset had more than one score reported, I tried to select the score that is the most informative. If multiple splits or variants of one dataset are reported, I tried to find the most informative subset.Results
ChatGPT won 34 out of 151 comparisons (22.5%). In most classical NLP tasks, ChatGPT does not outperform existing fine-tuned baselines, although it is often close. In some cases, it failed to beat even simple bag-of-words models (e.g., predicting agreeableness in Amin-Affective — 58.5 vs 44.8 accuracy) or it was worse than a supervised baselines by a surprisingly significant margin (e.g., CLUTRR relational reasoning dataset in Bang-Benchmark — 48.4 vs 23.3 accuracy or GoEmotions emotion classification dataset in Kocoń-Benchmark — 52.75 vs 25.55 accuracy). ChatGPT struggles with affective tasks (Kocoń-Benchmark, Amin-Affective), and it sometimes shows a higher level of brittleness than older BERT-tier models (Jang-Consistency). I was surprised to find that ChatGPT does not excel in text generation tasks such as summarization or question answering (Wang-Summarization, Tan-QA), even though people really like these capabilities. ChatGPT does not seem very strong with semantic similarity tasks, but it is really good at comparing generated texts to references (Kocmi-Evaluation, Wang-Evaluation). I thought that these two skills would be highly correlated, but I guess not.
Some of the papers (Qin-Understanding, Wang-Robustness, Hendy-Translation) also do a comparison with various versions of GPT-3. The results are a mixed bag and I can’t really find any pattern in the tasks where ChatGPT wins or fails. This shows a level of brittleness in the training process, where the model gets some capabilities, but it might lose others in return . confirm this, when they showed that ChatGPT is worse than
text-davinci-003 at several datasets and tasks, surprisingly including SQuAD question answering datasets.Caveats
There are several important caveats to consider. I have marked whether each caveat suggests that ChatGPT might be stronger (+) or weaker (-) than reported.
- Suboptimal utilization of ChatGPT (+). Prompt engineering can markedly improve LLM’s performance (e.g., 78.7 vs 86.2 score in Zhong-Understanding), but some of the papers here use only very basic prompting techniques. It was also quite obvious that some of the ChatGPT experiments were rushed last minute additions. As people will become more familiar with ChatGPT and appropriate prompting techniques in the future, the performance utilization may increase and ChatGPT might be able to get additional wins.
- Self-selected datasets (+). Researchers tend to design datasets so they can be solved by already available methods and approaches. I believe, that this is why some older classification datasets still have competitive results from bag-of-words approaches. The fine-tuned models might have good results because the datasets match their strong suit. On the other hand, many of the interesting ChatGPT’s abilities are currently difficult to measure due to the lack of appropriate datasets or methodologies, and they are therefore not included in this survey.
- Data leakage (-). It’s entirely possible that some of the datasets used for evaluation were leaked into the ChatGPT’s training set, which might have influenced the results. Some datasets are publicly available, and additional leaks might have occurred during ChatGPT usage. Researchers experimenting with GPT models often feed them raw data, and even labels if they use few-shot prompting. It’s unclear what OpenAI does with these data, and it’s possible that for many of the datasets, ChatGPT is already contaminated.
- Positive result bias (-). Researchers may not report when they are unable to make ChatGPT work on their particular dataset or use case.
- Weak baselines (-). Many of the baselines used for comparisons are not really the SOTA models anymore. You could probably find better models for some of the tasks that ChatGPT won.
- Mostly English. As is often the case, the evaluation of ChatGPT mainly focuses on the English language. Multilingual evaluation notoriously suffers from a lack of appropriate datasets.
Conclusion
I was, perhaps unjustly so, a bit disappointed by ChatGPT’s performance. It did not live up to the hype and to all the cherry-picked examples I have seen so far. It’s still a great generalist model, and it’s miraculous how many skills it can perform in some fashion. But this is still pretty far from a true linguistic intelligence. The small fine-tuned models are not that impressive for most of the classical NLP tasks and this is generally a little bit worse than that. I think that vanilla ChatGPT will be used as a quick prototype for some applications, but it will be replaced by a fine-tuned model (often smaller, for economical reasons) for most production-ready solutions, unless a free-text interaction will be required. I also wonder whether they will actually allow fine-tuning GPT-3.5 models (including ChatGPT) in the future. OpenAI has (again) raised the safety concerns around their models, and letting people fine-tune it would mean that they are breaking their own safety measures. I guess that they will do that eventually, as they did it will all their previous models.
It’s difficult to predict whether newer models will be significantly better than ChatGPT. The scaling paradigm is hitting a wall to some extent, both compute-wise and data-wise. The fact that exponential growth can not be sustained indefinitely should not be that surprising. We will have to wait a few months for a similar batch of papers to evaluate GPT-4, since the authors do not report anything outside of question answering in their paper. Their API page simply states that: For many basic tasks, the difference between GPT-4 and GPT-3.5 models is not significant. However, in more complex reasoning situations, GPT-4 is much more capable than any of our previous models. Does this mean that scaling stopped improving the basic capabilities completely and ChatGPT is basically the peak performance? On the other, hand the complex reasoning is perhaps the most interesting feature of these models right now and it is unfortunately mostly absent from this survey.
It seems that GPT-3 or even the older NLP models often have comparable capabilities, but ChatGPT got all the media attention. I guess this shows how important user experience really is. People do not care about smart auto-complete where they need to fiddle around with obscure parameters, such as temperature or top-p. But as soon as you package it as a chat and give it a little bit of personality, people will go crazy. I wonder about Galactica in this context. It probably could have been as successful as ChatGPT, only if they did not try to target the scientific community — a community where factuality, a well-known weakness of LLMs, is one of the most important values.
Evaluating LLMs is becoming increasingly difficult. The authors of the GPT models report results only on a handful of datasets, and the community needs to test the rest in an uncoordinated manner. Data leakage is a constant threat to the validity of the evaluation, and we will probably have to rethink it from the ground up. I can see user studies being used more in the future, but that will be even more costly. BIG-bench, a huge benchmark collection co-authored by 442 volunteer researchers and designed to test LLMs, was made practically completely useless for one of the most popular LLMs due to a data leak . It’s a bit pathological that academia is spending thousands of man-hours or dollars to test (read, to provide value to the model owners) completely closed-sourced models that can be taken down, updated, or contaminated at any time .
⁂
Appendix: Papers
Bang-Benchmark
Bang, Y., Cahyawijaya, S., Lee, N., Dai, W., Su, D., Wilie, B., ... & Fung, P. (2023). A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv preprint arXiv:2302.04023.
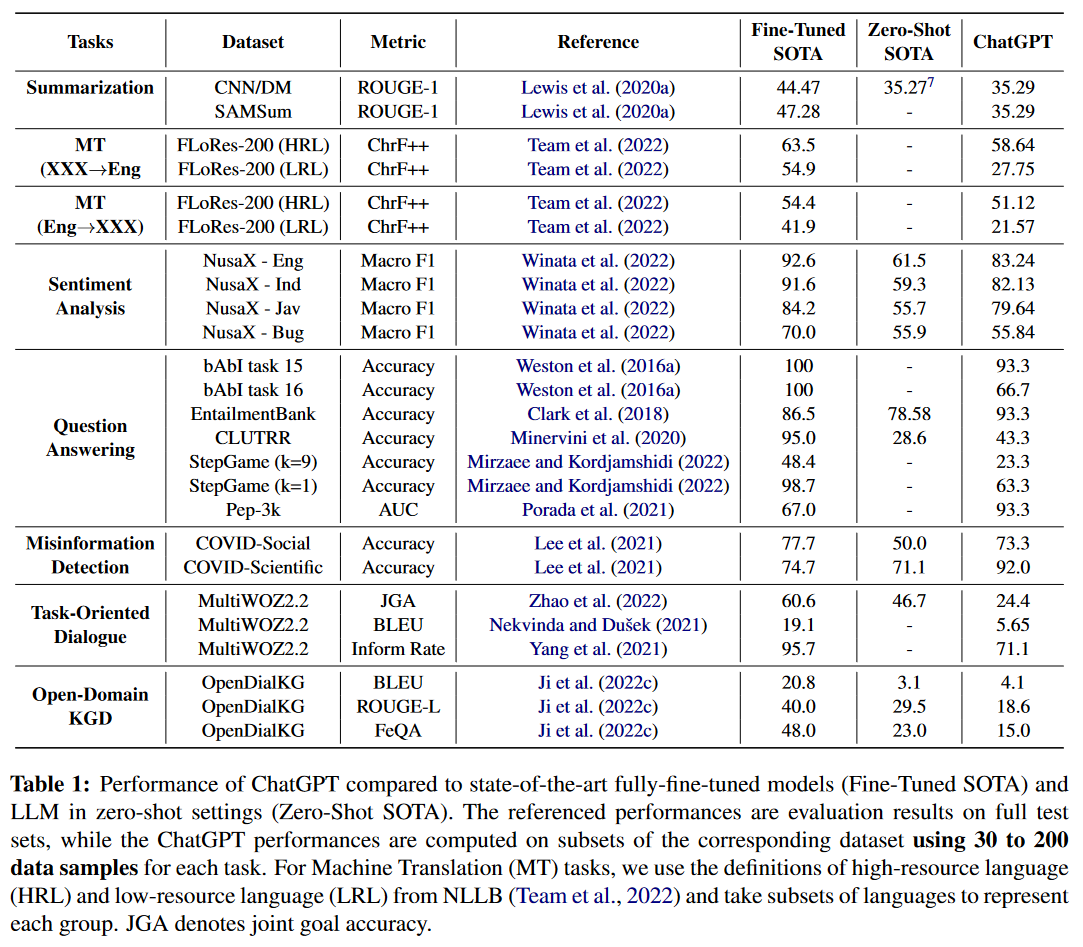
3 out of 21. This is the most thorough paper in this survey. They compared ChatGPT with fine-tuned and zero-shot SOTA on 21 datasets from 7 tasks: summarization, machine translation, sentiment analysis, question answering, misinformation detection, task-oriented dialogue, and open-domain knowledge-grounded dialogue. ChatGPT was able to win only in a small handful of cases. Additionally, they evaluated ChatGPT’s multilinguality, multimodality, reasoning capabilities, factuality, and interactivity, but that’s outside of my scope here. There is not much information about their prompt design, and they did not report confidence intervals for the scores, despite calculating them only from a small test sets (mostly 50 samples). Small samples size is actually a problem for many of the papers here, probably because of the limited API access people had.
I am skeptical about the COVID-Scientific dataset, which they describe as a testset that consists of COVID-19-related scientific or medical myths that must be debunked correctly to ensure the safety of the public. In my experience, it appears that ChatGPT was heavily reinforced to align its communication regarding COVID-19 in a particular manner and was likely exposed to significant amounts of texts about COVID-19 misinformation. The excellent performance on this dataset may be the result of what is essentially a data leak.
Kocoń-Benchmark
Kocoń, J., Cichecki, I., Kaszyca, O., Kochanek, M., Szydło, D., Baran, J., ... & Kazienko, P. (2023). ChatGPT: Jack of All Trades, Master of None. arXiv preprint arXiv:2302.10724.
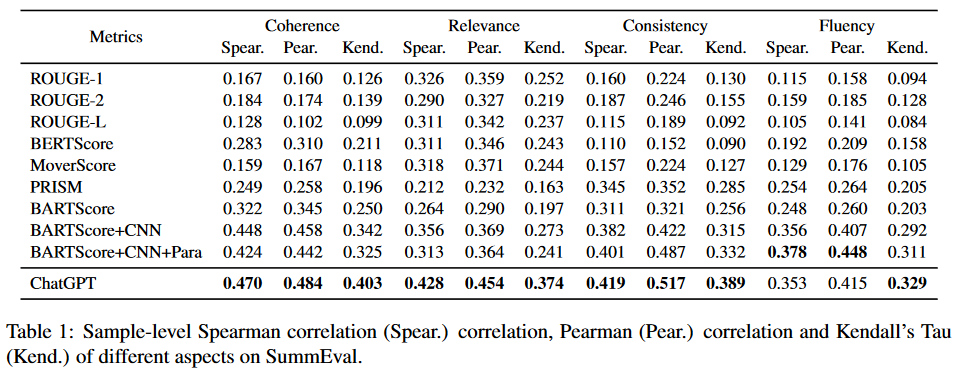
0 out of 25. This benchmarking paper analyzes ChatGPT’s performance on 25 datasets from 11 tasks: offensiveness detection, linguistic acceptability, humor recognition, spam detection, word sense disambiguation, natural language inference, question answering, emotion recognition, sentiment analysis, emoji prediction, and stance detection. Some of these tasks are in Polish. ChatGPT performed worse in all tasks, often by a significant margin. It particularly struggled with emotion and pragmatic tasks. They used few-shot prompting in some cases (AggressionPer and GoEmoPer datasets), while other tasks only had vanilla prompting.
They calculated some interesting correlations regarding the performance metrics. First, Figure 7 in their paper shows that ChatGPT seems to perform worse for more difficult tasks — tasks where SOTA is further away from 100% performance. This may suggest that ChatGPT struggles with long-tail tasks. Second, they estimated the probability of data leaking to ChatGPT for each dataset. Most datasets were marked as either probable or highly probable, which is alarming in its own right. Figure 10 shows that datasets with a lower leak probability had worse performance, suggesting that data leak might have inflated the results in some cases. However, I would like to see this without the GoEmoPer tasks, where ChatGPT was asked to imitate specific annotators based on 1-3 examples of their annotations. ChatGPT performed 30-47% worse than SOTA on these tasks, and it might have skewed the results.

Qin-Understanding
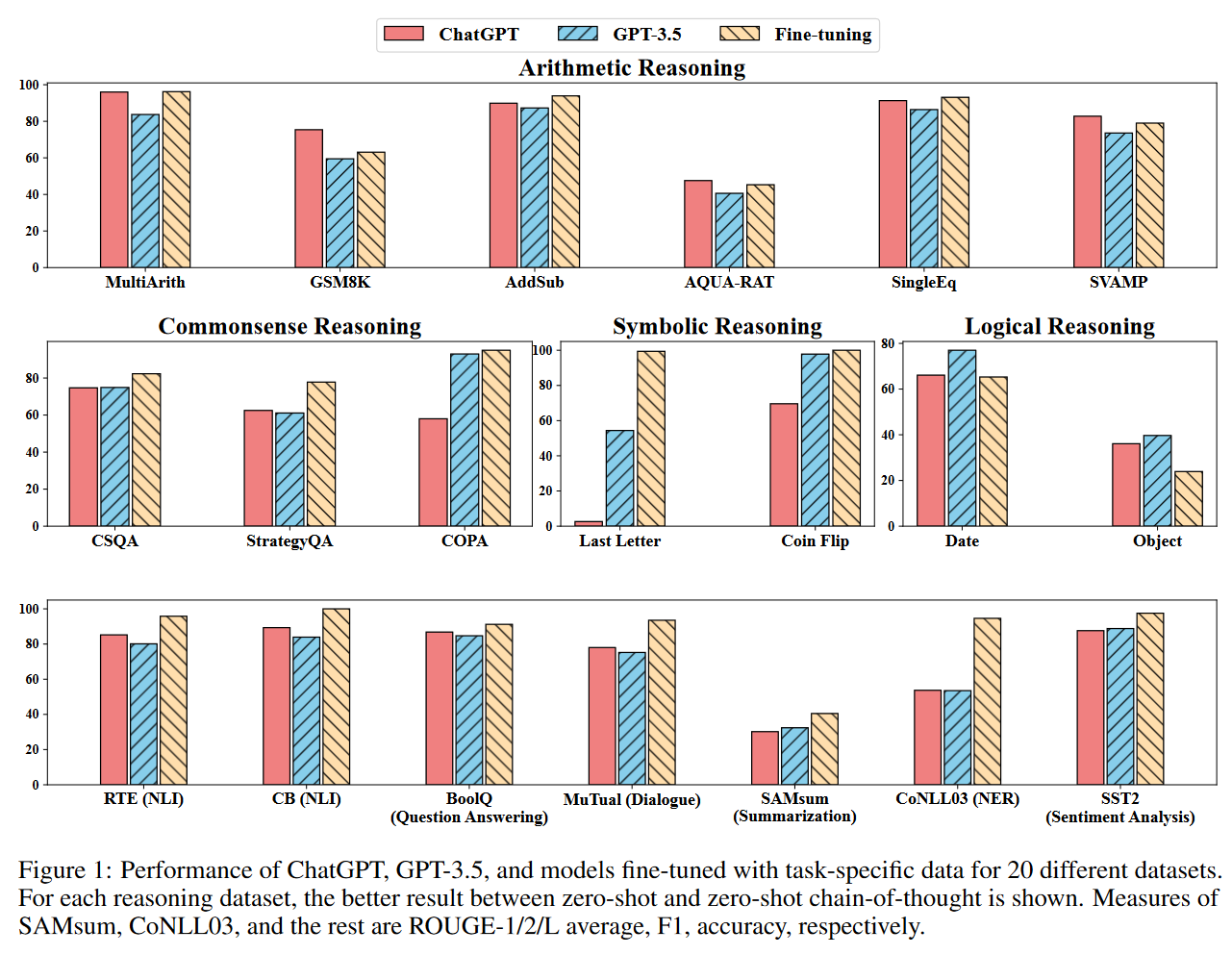
Qin, C., Zhang, A., Zhang, Z., Chen, J., Yasunaga, M., & Yang, D. (2023). Is ChatGPT a General-Purpose Natural Language Processing Task Solver? arXiv preprint arXiv:2302.06476.
0 out of 7. This is another paper that compares ChatGPT’s performance across a significant number of tasks. Figure 1 is actually misleading since the Fine-tuning models for all the Reasoning tasks (the first two rows of results) are also just language models prompted with chain-of-thought few-shot prompts. Therefore, I only consider the results from the last row where fine-tuned models are actually used. They outperform ChatGPT in all cases.
Zhong-Understanding
Zhong, Q., Ding, L., Liu, J., Du, B., & Tao, D. (2023). Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-tuned BERT. arXiv preprint arXiv:2302.10198.
1 out of 8. This is a comparison on the GLUE natural language understanding benchmark. They actually use some of the more advanced prompting strategies, including few-shot and chain-of-thought prompts. Their basic prompts were generated by ChatGPT, a bizzare decision, as I doubt that ChatGPT is self-conscious enough that it’s able to generate optimal prompts for itself. The prompting techniques helped to improve the average performance from 78.7 to 86.2.
ChatGPT arguably outperformed the RoBERTa-large model in 4 out of the 8 tasks reported here. However, in this case, I have decided to compare the performance with the GLUE leaderboard instead, as RoBERTa is a bit outdated by now. Compared to the true SOTA results (Turing ULR v6 model), ChatGPT performed better only for sentiment analysis. ChatGPT did not perform particularly well for sentiment analysis in the three previous papers, but they all used only vanilla prompts. The authors also discuss the instability of few-shot prompting. The performance for the CoLA dataset can differ by more than 20% depending on the selected examples.

Jang-Consistency
Jang, M., & Lukasiewicz, T. (2023). Consistency Analysis of ChatGPT. arXiv preprint arXiv:2303.06273.
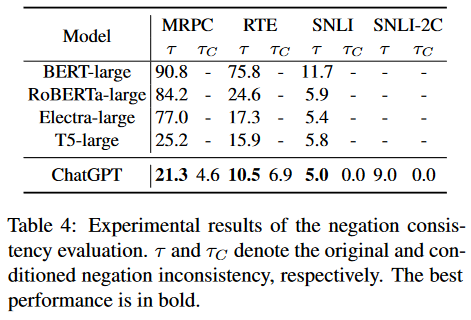
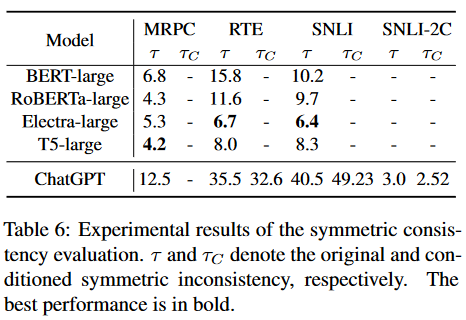
3 out of 9. The authors show that ChatGPT is surprisingly brittle when the input texts are perturbed, in some cases even more so than BERT-tier models. They tested two text comparison tasks (paraphrase detection and natural language inference) with three types of perturbations:
- Semantic perturbations. How do the predictions change if we paraphrase one of the inputs? The paraphrases were generated by Quilbot or ChatGPT. ChatGPT changes its prediction 10-30% of the time if we rephrase one of the inputs. It\s more consistent for paraphrases generated by itself.
- Negation perturbations. How do the predictions change if we negate the input? ChatGPT performs better than older models, which are notorious for not understanding negation . In this case, we expect negation to flip the prediction.
- Symmetric perturbations. How do the predictions change if we switch the order of the inputs? ChatGPT is incredibly inconsistent in this regard, much more so than any of the older models. MRPC is a completely symmetric task (do the two sentences have the same meaning?), but ChatGPT changes its prediction based on the order of the two sentences in 12.5% of cases. To improve the results, they had to merge neutral and contradiction labels into one in SNLI-2C. The fact that the model cannot distinguish between these two concepts is also concerning.

Wang-Robustness
Wang, J., Hu, X., Hou, W., Chen, H., Zheng, R., Wang, Y., ... & Xie, X. (2023). On the Robustness of ChatGPT: An Adversarial and Out-of-Distribution Perspective. arXiv preprint arXiv:2302.12095.
8 out of 8. The brittleness (or robustness) is the main topic of this paper as well. They test two scenarios: (1) adversarial attacks and (2) out-of-domain generalization. ChatGPT is the clean winner as it was able to achieve the best results in all cases. I specifically checked for possible data leaks for the adversarial datasets in this case, as this is the paper where ChatGPT has the best win ratio. There are a handful of samples leaked on the AdvGLUE benchmark website, but the biggest leak is probably HuggingFace Datasets page where they show 100 samples for each of the subsets tested here. Some of them are quite small (e.g., RTE has only 302 samples) and a large portion of the datasets could have been leaked this way. Otherwise, I don’t understand how ChatGPT became so much better than
text-davinci-003 in some cases .
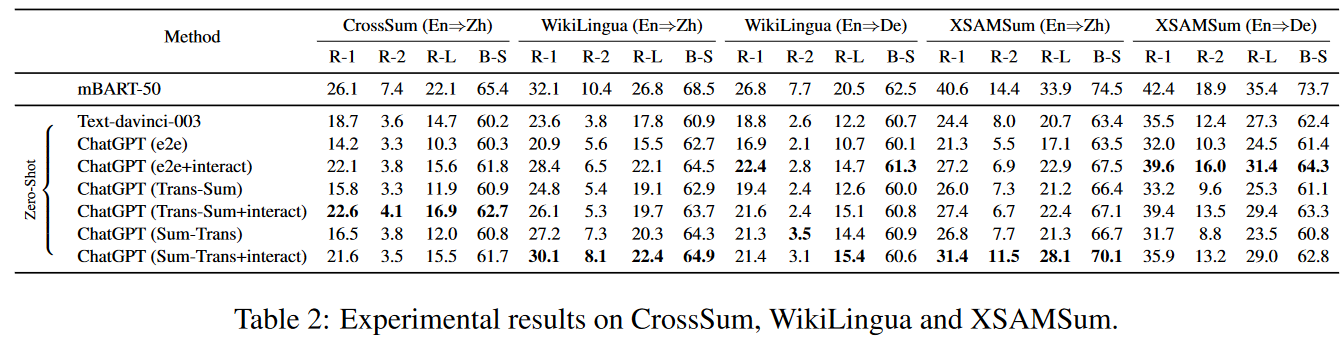
Wang-Summarization
Wang, J., Liang, Y., Meng, F., Li, Z., Qu, J., & Zhou, J. (2023). Cross-Lingual Summarization via ChatGPT. arXiv preprint arXiv:2302.14229.
0 out of 5. Qin-Understanding and Bang-Benchmark have already shown that ChatGPT does not beat the SOTA models for English summarization. Here, the authors show the same for crosslingual summarization (English to Mandarin and English to German). It could be argued that the evaluation metrics (mainly ROUGE) do not match the use case perfectly, and a user study should be conducted to see how people react to the outputs. On the other hand, Bang-Benchmark claim that the summaries produced by ChatGPT are sometimes longer than the input documents, so it’s hard to believe that ChatGPT really gets what this task is about.
Yang-Summarization
Yang, X., Li, Y., Zhang, X., Chen, H., & Cheng, W. (2023). Exploring the Limits of ChatGPT for Query or Aspect-Based Text Summarization. arXiv preprint arXiv:2302.08081.
2 out of 6. ChatGPT was actually able to achieve some summarization wins here, although the tasks are query-based and aspect-based summarization. Perhaps these tasks are better aligned with ChatGPT’s training. It wins an aspect-based NEWTS dataset and is also competitive for QMSum, where the task is to summarize a meeting transcript according to a specific query. The golden version only includes the parts of the meeting that are relevant to the input query.

Hendy-Translation
Hendy, A., Abdelrehim, M., Sharaf, A., Raunak, V., Gabr, M., Matsushita, H., ... & Awadalla, H. H. (2023). How Good are GPT Models at Machine Translation? A Comprehensive Evaluation. arXiv preprint arXiv:2302.09210.
1 out of 8. This paper is a pretty robust evaluation of the machine translation capabilities of the GPT models. The one experiment that uses ChatGPT is shown in the Figure below. The best performing models from the WMT benchmark outperformed the GPT models for most metrics. The comparison between
text-davinci-003 and ChatGPT is less clear and depends on the language. There are other experiments in the paper, but they do not use ChatGPT. The paper is actually exceptionally in-depth, and the follow-up investigation paints a much better picture of the capabilities of GPT models than the basic table shown here.Jiao-Translation
Jiao, W., Wang, W., Huang, J. T., Wang, X., & Tu, Z. (2023). Is ChatGPT a Good Translator? A Preliminary Study. arXiv preprint arXiv:2301.08745.
1 out of 16. This is another, in my opinion, weaker, machine translation paper. ChatGPT falls behind the available machine translation systems in almost all cases, except for one dataset, WMT20 Rob3 — an out-of-distribution test set based on transcribed speech. This is another paper that made the bizarre decision to ask ChatGPT for the prompts.
Kocmi-Evaluation
Kocmi, T., & Federmann, C. (2023). Large Language Models are State-of-the-Art Evaluators of Translation Quality. arXiv preprint arXiv:2302.14520.
1 out of 1. This paper has found that ChatGPT is an excellent evaluator of translations. GPT models have outperformed existing measures and models in terms of their alignment with human judgements. The performance of individual GPT models depends on the prompt formulation.
text-davinci-003 works best with a 0-100 scale, text-davinci-002 when it has to select 1-5 stars, and ChatGPT when it has to select from five text descriptions (e.g., No meaning preserved or Some meaning preserved, but not understandable).
Wang-Evaluation
Wang, J., Liang, Y., Meng, F., Shi, H., Li, Z., Xu, J., ... & Zhou, J. (2023). Is ChatGPT a Good NLG Evaluator? A Preliminary Study. arXiv preprint arXiv:2303.04048.
2 out of 3. This paper confirms the results from Kocmi-Evaluation and shows that ChatGPT is great for text evaluation. Instead of machine translation, they use summarization (SummEval), story generation (OpenMEVA), and data-to-text (BAGEL) tasks.


Tan-QA
Tan, Y., Min, D., Li, Y., Li, W., Hu, N., Chen, Y., & Qi, G. (2023). Evaluation of ChatGPT as a Question Answering System for Answering Complex Questions. arXiv preprint arXiv:2303.07992.
2 out of 8. The authors evaluated ChatGPT’s performance on 8 question answering datasets, including two multilingual ones. The results showed that ChatGPT’s performance varied significantly. It outperformed the SOTA model by a significant margin for WQSP, but fell completely behind for QALD-9. This unpredictability is not surprising, as question answering depends on two factors: (1) the number of answers in the training data, and (2) the number of answers the model memorized. These factors can vary significantly for questions from different domains or languages. The authors also observed that ChatGPT is less stable for similar/nearly identical inputs (see also Jang-Consistency).

Omar-QA
Omar, R., Mangukiya, O., Kalnis, P., & Mansour, E. (2023). ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots. arXiv preprint arXiv:2302.06466.
1 out of 4. This is another paper that evaluates question answering, but they focus on knowledge graphs. ChatGPT performs reasonably well on the general knowledge datasets (YAGO and QALD-9), but it fails completely on the academic datasets (DBLP and MAG). These academic datasets have questions about the virtual academic knowledge graph of authors, publications, and citations. Theoretically, ChatGPT has seen most of this graph during the training, but it’s obviously unable to infer this level of information from the raw text data. Compared to Tan-QA, the non-GPT baselines used here are actually quite weak (the SOTA models have F1 in 80s for the QALD-9).

Wei-Extraction
Wei, X., Cui, X., Cheng, N., Wang, X., Zhang, X., Huang, S., ... & Han, W. (2023). Zero-Shot Information Extraction via Chatting with ChatGPT. arXiv preprint arXiv:2302.10205.
2 out of 6. This paper evaluates three information extraction tasks: entity-relation triple extraction (RE), named entity recognition (NER), even extraction (EE). They report the results for Mandarin and English, with the first dataset for all three tasks in the table below being Mandarin. They compared fine-tuning smaller models (full-shot for normal fine-tuning or fs-x for few-shot tuning) with vanilla ChatGPT prompting (single), and a more complex multi-turn ChatGPT dialogue (ChatIE). Don’t get fooled by the bolded results. The fine-tuned baselines are mostly better. ChatGPT performed poorly for NER but was able to outperform full-shot solutions for Mandarin RE and EE.

Gao-Extraction
Gao, J., Zhao, H., Yu, C., & Xu, R. (2023). Exploring the Feasibility of ChatGPT for Event Extraction. arXiv preprint arXiv:2303.03836.
0 out of 1. This paper evaluates event extraction on the ACE dataset. The results are calculated only from a handful of samples (20 for each category), there are no confidence intervals, and the F1 score for ChatGPT Simple Examples does not make sense given the Precision and Recall values. The authors split the samples based on the event frequency (how many times that event is mentioned in the training dataset) and the sample complexity (how many events are in one sample), but the results are all over the place, likely due to the small size of the test sets.

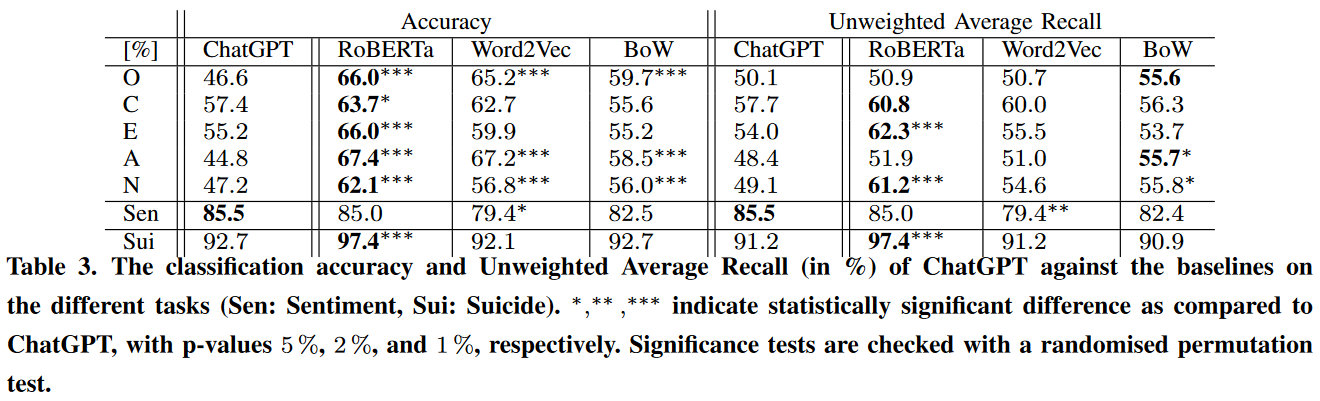
Amin-Affective
Amin, M. M., Cambria, E., & Schuller, B. W. (2023). Will Affective Computing Emerge from Foundation Models and General AI? A First Evaluation on ChatGPT. arXiv preprint arXiv:2303.03186.
1 out of 7. A very straightforward comparison between ChatGPT and a set of rather simple baselines for three affective classification tasks: big-five personality prediction, sentiment analysis, and suicide tendency detection. ChatGPT’s results are really not impressive and it managed to win only sentiment analysis. In some cases, it was beaten even by a bag-of-words approach. Note that Kocoń-Benchmark also claim that ChatGPT does not work well on emotional tasks. ChatGPT managed to win sentiment analysis in this paper and in Zhong-Understanding, but in both cases it was only compared to RoBERTa. When it’s compared with the SOTA models, it falls behind (Bang-Benchmark, Kocoń-Benchmark, Qin-Understanding).
Kuzman-Genre
Kuzman, T., Mozetič, I., & Ljubešić, N. (2023). ChatGPT: Beginning of an End of Manual Linguistic Data Annotation? Use Case of Automatic Genre Identification. arXiv preprint arXiv:2303.03953.
1 out of 2. A very straight-forward paper where they compare ChatGPT with an XLM-RoBERTa based fine-tuned model for genre classification. They use English (EN-GINCO) and Slovenian (GINCO) datasets. ChatGPT performed better on the English one.

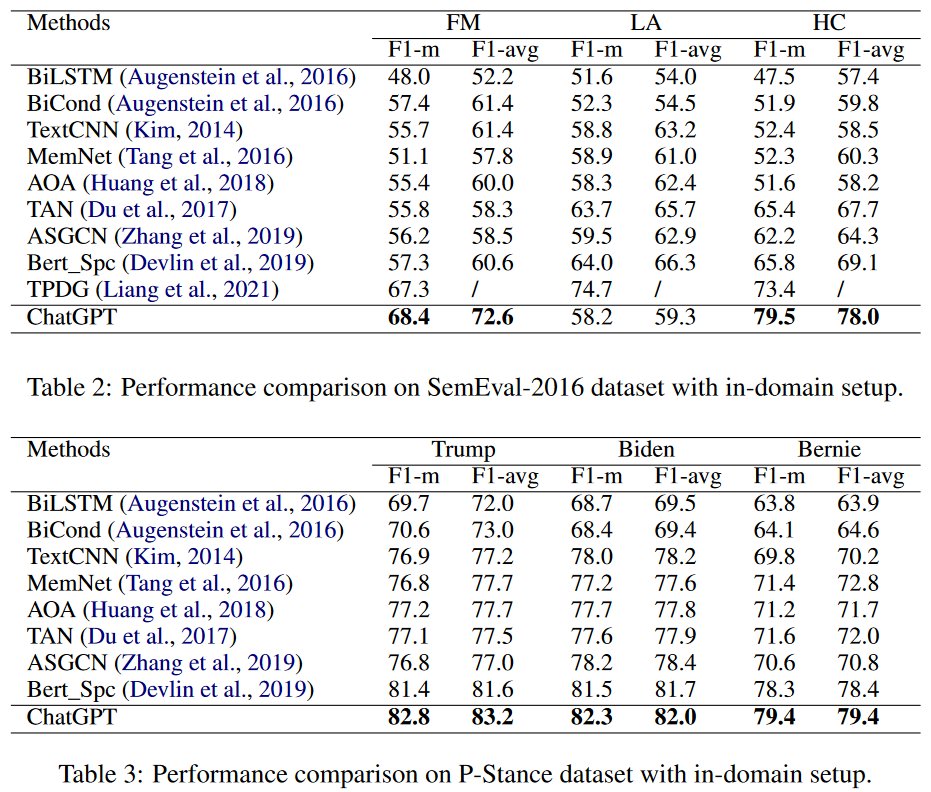
Zhang-Stance
Zhang, B., Ding, D., & Jing, L. (2022). How would Stance Detection Techniques Evolve after the Launch of ChatGPT?. arXiv preprint arXiv:2212.14548.
5 out of 6. They evaluate the performance on stance detection, which is a task that aims to identify whether a text is in favor of or against something. They used two datasets, the first of which contains texts about the feminist movement (FM), the legalization of abortion (LA), and Hillary Clinton (HC). The second dataset is about US politicians. ChatGPT outperformed SOTA in 5 out of 6 splits, with the only exception being the abortion split.
⁂
Cite
@misc{pikuliak_chatgpt_survey,
author = "Matúš Pikuliak",
title = "ChatGPT Survey: Performance on NLP datasets",
howpublished = "https://www.opensamizdat.com/posts/chatgpt_survey",
month = "03",
year = "2023",
}
⁂